透過OpenMP撰寫平行化運算程式.以下是用Ubuntu 16.04 環境進行測試.
測試如何使用OpenMP的函式庫:
安裝相關編譯用套件
$ sudo apt install libomp-dev
$ sudo apt-get install clang test.c
#include "omp.h"
#include <stdio.h>
int main(void) {
#pragma omp parallel
printf("thread %d\n", omp_get_thread_num());
}
clang test.c -fopenmp
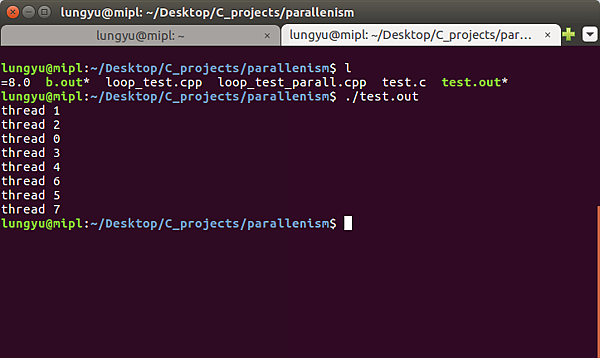
以下測試實際平行化運算下,是否能有所提昇.
loop_test.cpp
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
void Test( int n ){
for( int i = 0; i < 10000; ++ i ){
//do nothing, just waste time
}
printf( "%d, ", n );
}
int main(int argc, char* argv[]){
for( int i = 0; i < 10; ++ i )
Test( i );
std::cout << std::endl;
}
loop_test_parall.cpp
#include <omp.h>
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
void Test( int n ){
for( int i = 0; i < 10000; ++ i ){
//do nothing, just waste time
}
printf( "%d, ", n );
}
int main(int argc, char* argv[]){
#pragma omp parallel for
for( int i = 0; i < 10; ++ i )
Test( i );
std::cout << std::endl;
}
分別將兩個檔案進行編譯:
g++ loop_test.cpp -o a.out
g++ loop_test_parall.cpp -o b.out -fopenmp

由實驗結果可以發現,由於還要額外增加分配之相關作業,因此若被分割的單元不夠複雜可能會造成效能反而下降.
並且可以看到由於分配到不同cpu執行,而cpu之間工作的切換是由作業系統決定的,因此會造成每個區段的時間不一.
因此再做平行化運算的時候須嚴加考慮,否則可能會出現難以預測的問題.
文章標籤
全站熱搜

 留言列表
留言列表

 {{ article.title }}
{{ article.title }}